
Background
- 프로그램을 실행하려면 디스크에서 메인 메모리로 가져와 프로세스 내에 배치해야 함
- 메인 메모리 및 레지스터는 CPU만 직접 액세스할 수 있음, instruction이나 data를 읽어옴
- 메모리 장치에는 주소 스트림 + 읽기 요청 또는 주소 + 데이터 및 쓰기 요청만 표시됨
- 레지스터는 하나의 CPU 클럭(또는 그 이하)에 접근, CPU 칩 안의 저장 매개체로 접근 속도 빠름
- 메인 메모리는 많은 사이클이 소요되어 stall이 발생할 수 있음
- Cache는 메인 메모리와 CPU 레지스터 사이에 위치
- register와 메인 메모리에서 data, instruction을 가져오는 처리 속도의 차이 때문에 cache 필요
- 메모리 보호는 올바른 작동을 보장하는 데 필요함
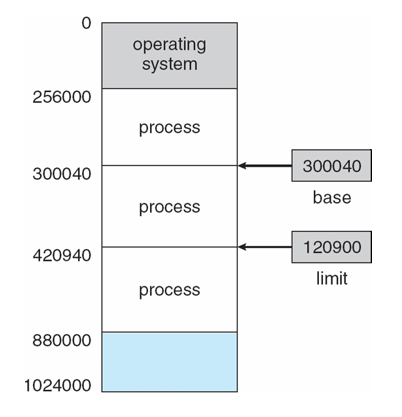
Base and Limit Registers
- base and limit registers 쌍은 logical address space를 정의함
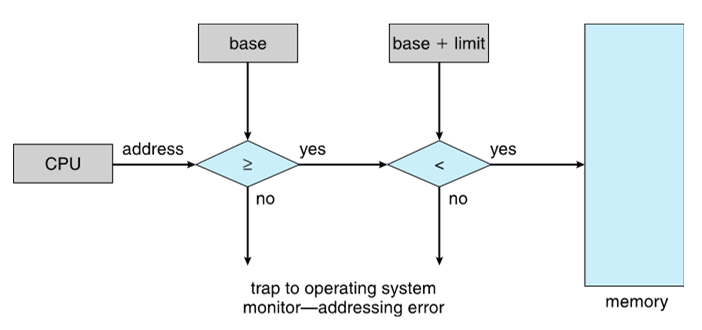
- CPU는 user mode에서 생성된 모든 메모리 액세스를 확인하여 해당 사용자에 대한 base와 limit 사이에 있는지 확인
- base : 메모리 공간 할당 받을 때 결정, base register에 저장, 시작 주소
- limit : 프로세스의 최대 길이, 프로세스의 메모리 할당 크기를 나타냄, limit register에 저장
- context switch에 base, limit이 결정되고 PCB안에 저장됨
- CPU는 base보다는 크고 base + limit보다는 작은 instruction이나 데이터를 가져와야 함
Hardware Address Protection
- Compile time과 같이 메인 메모리에 저장되기 전에 물리 주소가 결정되는 경우
- 초기 기법에서 CPU가 생성하는 address는 memory address (physical address)
- trap - 소프트웨어 인터럽트
Address Binding
- instruction, data address를 어떻게 할당하는가?
- 메모리로 가져와 실행할 준비가 된 디스크의 프로그램이 input queue를 형성
- 지원하지 않는 경우 address 0000에 로드해야 함
- 0000에서 첫 번째 사용자가 물리적 주소를 항상 처리하도록 하는 것이 불편함
- 주소는 프로그램 life의 다른 단계에서 서로 다른 방식으로 표현됨
- 소스 코드 주소는 일반적으로 symbolic, 소스 프로그램에서 address를 symbolic하게 언급
- statement 앞에 라벨이 붙어 라벨이 주소 역할을 함
- instruction의 상대 위치를 나타냄
- 컴파일된 코드 주소가 재배치 가능한 주소(프로그램의 상대적 위치를 나타냄)로 바인딩됨
- ex) "이 모듈의 시작 부분부터 14바이트"
- Linker 또는 loader가 메모리에 적재될 때 재배치 가능한 주소를 절대 주소(physical address)로 바인딩함(초기)
- Linker : 시스템 라이브러리 or 프로그램 바깥의 라이브러리와 연결시켜줌
- Loader : 이미지를 메인 메모리에 로드시켜주는 모듈
- 각 바인딩은 하나의 주소 공간을 다른 주소 공간에 매핑
- 소스 코드 주소는 일반적으로 symbolic, 소스 프로그램에서 address를 symbolic하게 언급
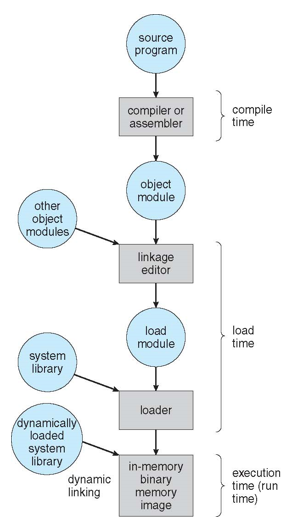
Binding of Instructions and Data to Memory
- 메모리 주소에 대한 instructions와 data의 address binding은 세 가지 단계에서 발생
- compile time, load time은 중간에 swap out 되었다가 swap in 될 때도 같은 address로 들어감
- Compile time
- compile time에 physical address 결정
- 메모리 위치가 미리 알려진 경우 절대 코드(absolute code)가 생성될 수 있음
- start address가 변경되면 코드를 다시 compile해야 함
- 속도가 빠르지만 프로세스에게 항상 해당 부분이 할당되어야 해 메모리 효율성이 낮음
- Load time
- 컴파일 시 메모리 위치를 알 수 없는 경우 재배치 가능한 코드를 생성해야 함
- compile time에는 재배치 주소로 결정되고, 메모리에 적재될 때 physical address 결정 (수행되기 전)
- Execution time - 현대
- 프로세스를 실행하는 동안 메모리 세그먼트 간에 이동할 수 있는 경우 실행 시간까지 바인딩이 지연됨
- 수행될 때 메모리 주소(physical address)가 결정됨
- address maps(예: base and limit registers)에 대한 하드웨어 지원 필요
- swap out → swap in 할 때 얼마든지 다른 부분에 할당 가능
Multistep Processing of a User Program
- 유저 프로그램이 메인 메모리에 로드되기 전까지의 과정
- 현대에는 linker, loader가 compiler의 일부분
- dynamic linking - ex) standard C library
Logical vs Physical Address Space
- 별도의 physical address space에 바인딩된 logical address space의 개념은 적절한 메모리 관리의 핵심
- Logical address – CPU에 의해 발생되는 address로, virtual address라고도 함 (CPU는 프로세스에서 instruction or 데이터의 상대주소로 address 특정), 0부터 시작하는 offset
- Physical address – 메모리 장치가 인식하는 주소
- compile-time 및 load-time에 주소 할당(address-binding)이 이루어지는 경우에 Logical address와 physical address가 동일함
- 메모리에 적재된 다음에 CPU에 의해 instruction이 수행되기 때문
- execution-time address-binding 체계에서 Logical address(virtual address)와 physical address는 다름
- 주소가 계속 바뀌기 때문
- logical address - 프로그램에서의 상대적 위치, offset
- physical address - 메인 메모리의 물리 주소
- Logical address space은 프로그램에 의해 생성된 모든 logical address의 집합
- Physical address space은 프로그램에 의해 생성된 모든 physical address의 집합
Memory-Management Unit (MMU)
- CPU에서 발생되는 virtual address를 physical address로 바꿔주는 하드웨어 디바이스
- 메모리 정보 (base, limit) → PCB에 저장
- relocation register의 값이 메모리로 전송될 때 사용자 프로세스에 의해 생성된 모든 address에 추가되는 간단한 방식을 고려
- relocation register라고 하는 base register
- Intel 80x86의 MS-DOS에서 4개의 relocation registers 사용
- 사용자 프로그램은 logical addresses를 처리하고, 실제 physical addresses는 보지 못 함
- Execution-time binding인 경우 주소 할당이 수행시에 발생
- physical addresses에 바인딩된 Logical address
Dynamic relocation(동적 적재) using a relocation register
- compile → 모든 루틴이 디스크에 저장 → 언제 메인 메모리로?
- 호출될 때까지 루틴이 적재되지 않음, 루틴이 수행될 때 메인 메모리에 적재
- 필요한 부분만 로드하므로 메모리 공간 활용도 향상, 사용하지 않는 루틴은 로드되지 않음
- 재배치 가능한 로드 형식으로 디스크에 보관된 모든 루틴
- 자주 발생하지 않는 일들을 처리하기 위해 많은 양의 코드가 필요할 때 유용
- OS의 특별한 지원이 필요하지 않음, OS 개입 X
- 프로그램 설계를 통해 구현
- OS는 동적 로딩을 구현하기 위한 라이브러리를 제공함으로써 도움은 될 수 있음
- 초기에는 수행될 때 로드 → 시간 오래 걸림
- 현대에는 미리 예측해서 수행 전에 로드 → ex) locality
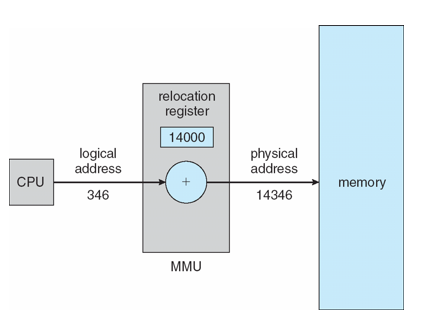
- logical address → 상대적 offset
- relocation register 값 → 프로세스의 시작 address
- limit > logical address → valid
- limit를 넘어서지 않았다면 virtual address + relocation address가 physical address 결정됨
Dynamic Linking (동적 연결)
- Static linking
- 로더에 의해 이진 프로그램 이미지로 결합된 시스템 라이브러리 및 프로그램 코드
- compile 되고 메모리에 적재되기 전에 시스템 라이브러리와 프로그램 코드가 합쳐짐
- 하나마다 라이브러리랑 합쳐짐 → 중복된 copy ↑ → 메인 메모리 낭비가 심함, binary image 크기 ↑
- 라이브러리를 여러 프로세스가 공유하는 기법이 없음
- Dynamic linking
- execution time에 linking, 프로그램이 메인 메모리에 로드되고 필요할 때 라이브러리와 합쳐짐
- 하나의 라이브러리가 메인 메모리에 들어가면 여러 개의 프로세스가 공유 가능
- 메인 메모리 안에 적재될 때 내 프로그램만 들어가면 되므로 이미지의 크기가 줄어듦 → 메모리 공간 활용도↑
- execution time에 linking, 프로그램이 메인 메모리에 로드되고 필요할 때 라이브러리와 합쳐짐
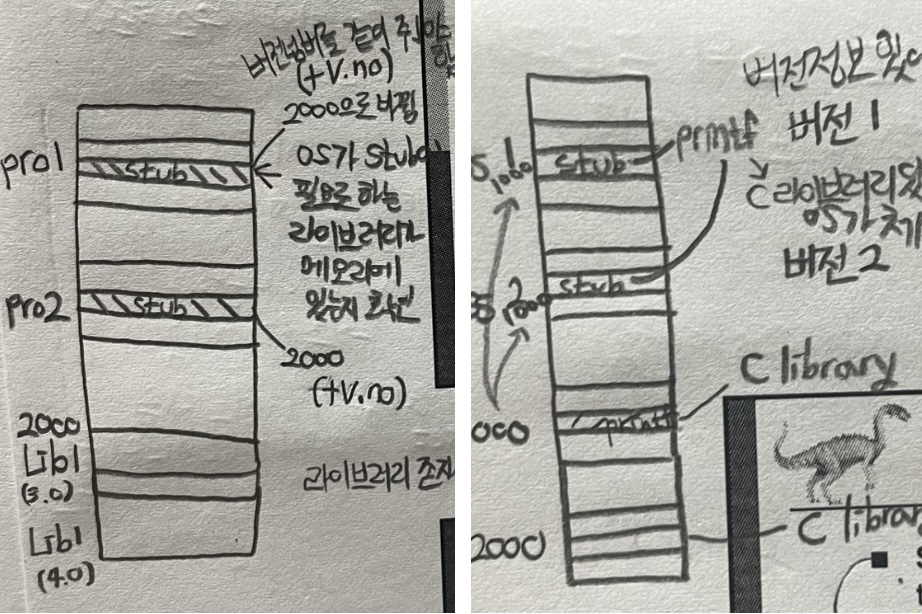
- 적절한 memory-resident library 루틴을 찾는 데 사용되는 작은 코드 조각, stub
- stub이 루틴의 주소로 자신을 대체하고 루틴을 실행 (각각의 프로세스는 stub 안에 버전 넘버를 가지고 있어야 함, 라이브러리도 버전 넘버 가지고 있어야 함)
- OS는 루틴이 프로세스의 메모리 주소에 있는지 확인
- address space에 없는 경우 address space에 추가
- Dynamic linking은 라이브러리에 특히 유용
- 시스템은 shared libraries(공유 라이브러리)라고도 함
- patching system libraries에 대한 적용 가능성 고려 → 버전 관리가 필요할 수 있음
- OS 지원 반드시 필요
OS가 해야하는 일
- 실행 중인 프로세스 바깥에서 라이브러리가 존재하는지 확인, 존재하지 않는다면 disk로부터 MM로 가져옴
- 프로세스가 라이브러리를 공유할 수 있도록 만들어줌
Swapping
- 메모리 부족 상태에서 프로세스를 일시적으로 backing store로 swap한 다음, 다시 메모리로 가져와 실행
- 프로세스의 총 물리적 메모리 공간이 물리적 메모리를 초과할 수 있기 때문
- 프로세스 전체 크기 > 프로세스를 위해 할당된 메모리 크기일 경우
- 백업 저장소(backing store) – 모든 사용자가 사용할 수 있는 모든 메모리 이미지의 복사본을 수용할 수 있을 정도로 빠른 디스크. 이러한 메모리 이미지에 직접 액세스할 수 있어야 함
- Roll out, roll in – 우선순위 기반 스케줄링 알고리즘에 사용되는 변수 swap함. 우선순위가 낮은 프로세스는 우선순위가 높은 프로세스를 로드하고 실행할 수 있도록 swap됨
- swap time의 주요 부분은 transfer time, 총 전송 시간은 swap된 메모리 양에 정비례
- transfer time - backing store에서 MM로 들어오거나 나가는 시간
- 시스템이 disk에 메모리 이미지가 있는 실행 준비 완료 프로세스 ready queue를 유지
- swap out된 프로세스를 동일한 물리적 주소로 다시 swap?
- address binding 방법에 따라 다름
- + 프로세스 메모리 공간에 대한 보류 중인 I/O를 고려
- address binding 방법에 따라 다름
- 많은 시스템(예: UNIX, Linux 및 Windows)에서 swapping의 수정 버전을 찾을 수 있음
- swapping이 일반적으로 disabled
- 할당된 메모리의 임계값보다 많은 경우 시작됨
- 메모리 요구량이 임계값 미만으로 감소하면 다시 disable됨
Schematic View of Swapping
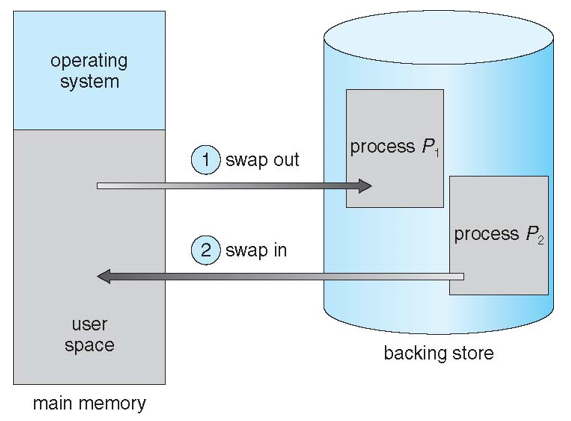
- 초기 → 전체 프로세스를 swap out, swap in → context switch time이 커지는 문제
- 현대 → 프로세스의 일부분, 필요한 부분만 swap
Context Switch Time including Swapping
- CPU를 할당 받을 다음 프로세스가 메모리에 없으면 프로세스를 swap out하고 대상 프로세스를 swap in
- context switch time이 매우 길어질 수 있음
- 50MB/초의 전송 속도로 하드 디스크로 100MB 프로세스 swapping
- 2000ms의 swap out time, swap in time
- total context switch swap 구성 요소 시간 4000ms(4초)
- 실제 사용되는 메모리 양을 파악하여 스왑되는 메모리 크기를 줄이면 단축 가능 (필요한 부분만, 필요할 때만 swapping)
- 필요할 때만 swapping
- swap out size 줄이기
- request_memory() 및 release_memory()를 통해 OS에 메모리 사용을 알리기 위한 시스템 호출
Context Switch Time and Swapping (Cont.)
- swapping시 기타 제약 조건
- 보류 중인 I/O – 잘못된 프로세스로 인해 I/O가 발생하므로 swap할 수 없음
- 또는 항상 I/O를 커널 공간으로 전송한 다음 I/O 장치로 전송
- double buffering으로 알려져 있으며 오버헤드를 추가
- I/O 수행 중 swapping X
- 일일히 체크하기 힘드므로 read/write 수행시 커널 공간에 들어오고 나중에 필요한 유저 프로세스에게 copy
- double buffering - 들어온 buffer에서 유저 프로세스로 copy되고 disk로부터 buffer로 들어오는 과정을 동시에 진행해 transfer time을 줄임
- standard swapping은 현대 운영 체제에서 사용되지 않음
- 그러나 수정된 버전은 공통
- 사용 가능한 메모리가 매우 낮은 경우에만 swap
Contiguous Allocation
- 메인 메모리는 OS 및 사용자 프로세스를 모두 지원
- 제한된 리소스, 효율적으로 할당해야 함
- 연속 할당은 초기 방법 중 하나
- 메인 메모리는 일반적으로 두 개의 파티션으로 나뉨 - kernel, user
- Resident OS, 일반적으로 인터럽트 벡터가 있는 low memory에 저장됨, kernel - low memory
- 유저 프로세스가 대용량 메모리(high memory)에 저장됨
- 메모리의 단일 연속 섹션에 포함된 각 프로세스
- fixed-partition (고정 분할)
- 똑같은 크기로 메모리를 나눔
- user, kernel 파티션
- paging으로 발전
- variable-partition (가변 분할)
- 파티션 크기가 서로 다름
- 프로세스가 필요한 부분만 할당해 자신의 영역 중 못 쓰는 영역이 없음
- segmentation으로 발전
공통
- 한 파티션에 한 프로세스, 파티션의 개수가 multiprogramming 정도 결정
- 파티션의 개수 = 메모리에 존재할 수 있는 프로세스 개수
fixed-partition과 paging
- 같은 점
- partition/page에 들어갈 수 있는 프로세스 : 1
- 파티션 안에 쓰지 못하고 남는 공간을 나타내는 internal fragmentation (내부 단편화)
- 다른 점
- size가 다름
- page는 사이즈가 작아 한 프로세스의 크기가 크면 비연속적인(non-contigous) 페이지에 들어감
- ex) 15KB의 프로세스, 4KB의 페이지 → 4개의 페이지(16KB) 할당
- partition은 사이즈가 커 한 파티션 안에 프로세스 하나가 다 들어감
- page는 사이즈가 작아 한 프로세스의 크기가 크면 비연속적인(non-contigous) 페이지에 들어감
- 내부 단편화에서의 차이
- page는 가장 마지막 페이지에 내부 단편화가 발생, fixed-partition보다 내부 단편화의 크기 작음
- partition은 한 파티션에 한 프로세스만 들어가 내부 단편화가 발생함
- size가 다름
variable-partition과 segmetation
- 같은 점
- 필요한 부분만 할당받고, swap out 됐을 때 해당 메모리의 크기가 다음에 들어오는 프로세스 크기보다 작으면 비어있는 공간이 생겨 못 쓰는 공간이 됨 - external fragmentation (외부 단편화)
- 다른 점
- partition은 한 파티션에 한 프로세스가 들어감
- segment는 세그먼트에 프로세스의 여러 영역이 분할되어 저장됨, 한 세그먼트 안에는 프로세스의 한 구성요소가 들어감
Cotiguous Allocation (Cont.)
- 사용자 프로세스를 서로 보호하고 운영 체제 코드 및 데이터를 변경하지 못하도록 하는 데 사용되는 재배치 레지스터, limit 레지스터
- base register에 최소 물리 주소 값 포함
- limit register에 포함된 논리 주소 범위 - 각 논리 주소는 limit register보다 작아야 함
- MMU는 논리 주소를 동적으로 매핑
- 그런 다음 커널 코드가 일시적이고 커널 크기가 변경되는 등의 작업을 허용 (필요없는 부분 제외)
- transient code, transient kernel - 일시적인 코드, 커널에서 필요 없는 부분을 제외하고 커널을 메모리 안에 집어넣음 → 메모리 안에 로드되는 커널의 크기가 바뀌는 것 - 메모리를 활용도 있게 사용 가능
Hardware Support for Relocation and Limit Registers
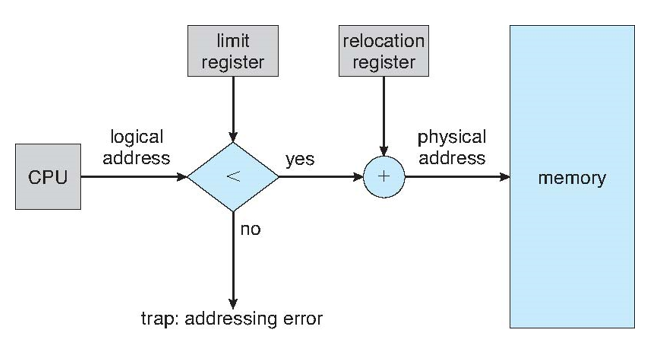
- logical address - 상대위치, offset
- limit register - 프로세스가 가질 수 있는 메모리의 최대 크기
Multiple-partition allocation
- 파티션 수에 따라 제한된 multiprogramming 정도
- 효율성을 위한 다양한 파티션 크기 (특정 프로세스 요구에 맞게 크기 조정)
- Hole – 사용 가능한 메모리 블록, 다양한 크기의 hole이 메모리 전체에 흩어져 있음
- 프로세스가 도착하면, 프로세스를 수용할 수 있을 만큼 큰 hole에 메모리가 할당됨
- 프로세스 종료 시 파티션이 해제되고, 인접한 사용 가능한 파티션이 결합됨
- 운영 체제는 다음에 대한 정보를 유지
- a) 할당된 파티션
- b) 사용 가능한 파티션 (hole)
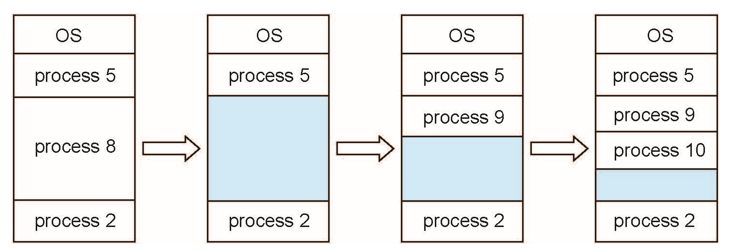
- 2번째 그림에서 hole이 생김 - 현재는 fragmentation이 아님
- hole 중에서 어떤 프로세스도 들어갈 수 없는 크기의 hole이 fragmentation
Dynamic Storage-Allocation Problem
- free holes의 목록에서 n 크기의 요청을 어떻게 충족시킬 수 있을까?
- First-fit
- 충분한 크기의 첫 번째 hole 할당
- 프로세스가 들어갈 수 있는 첫 번째 공간에 들어감
- 성능이 좋지만, 프로세스가 한쪽으로 몰리게 되어 뒤의 메모리 공간 활용도가 떨어짐
- Next-fit
- 마지막 프로세스가 할당된 다음 공간부터 시작해 들어갈 수 있는 공간 찾음
- 프로세스가 차지하는 메모리 공간이 분산됨
- Best-fit
- 크기가 충분한 가장 작은 hole을 할당
- 크기별로 정렬되지 않은 한 전체 목록을 검색해야 함
- 가장 작은 잔여 hole 생성 - 들어가고 가장 적은 공간이 남는 공간에 할당 → 외부 단편화
- Worst-fit
- 가장 큰 hole 할당, 전체 목록도 검색해야 함
- 가장 큰 잔여 hole 생성
- 할당한 후 남는 공간이 크면 다른 프로세스가 들어갈 확률이 높아짐
- 속도 및 저장 공간 활용률 측면 : First-fit, Best-fit > Worst-fit
Fragmentation
- External Fragmentation (외부 단편화)
- 요청을 충족하기 위한 총 메모리 공간이 존재하지만 연속되지는 않음
- 프로세스가 차지한 메모리 공간 바깥에 단편화가 생기는 공간
- Internal Fragmentation (내부 단편화)
- 할당된 메모리가 요청된 메모리보다 약간 클 때, 파티션 내부의 메모리이지만 사용되지는 않음
- 한 파티션 안에 있는 못 쓰는 공간
- First-fit에서는 할당된 N개의 블록에서 0.5개의 블록이 단편화로 손실됨
- 1/3은 사용할 수 없을 것임 -> 50-percent rule
Fragmentation (Cont.)
- compaction을 통해 external fragmentation 감소 (garbage collection)
- 메모리 공간을 한쪽으로 밀어 사용 가능한 모든 메모리를 하나의 큰 블록으로 함께 배치
- → memory compaction으로 프로세스에 할당된 메모리 주소가 바뀜
- 재배치가 동적이고 execution-time시 address binding이 수행되는 경우에만 memory compaction이 가능
- compile-time, load-time에 address binding이 수행된다면 memory compaction 사용 불가능
- I/O problem
- I/O와 관련된 동안 메모리에 작업 상태를 유지시킴
- I/O를 OS 버퍼에만 적용
- 바뀌지 않는 kernel 영역에 I/O 작업을 받아 memory compaction으로 새로운 영역에 할당시킨 후 copy
- 이제 backing store에 동일한 fragmentation 문제가 있다고 가정해보자
- 메모리 공간을 한쪽으로 밀어 사용 가능한 모든 메모리를 하나의 큰 블록으로 함께 배치
Segmentation
- user view of memory를 지원하는 메모리 관리 체계
- 프로그램은 세그먼트의 모음 (비연속적인 segment 안에 저장)
- 세그먼트는 다음과 같은 논리 단위
main program
procedure
function
method
object
local variables, global variables
common block
stack
symbol table
arrays
User’s View of a Program
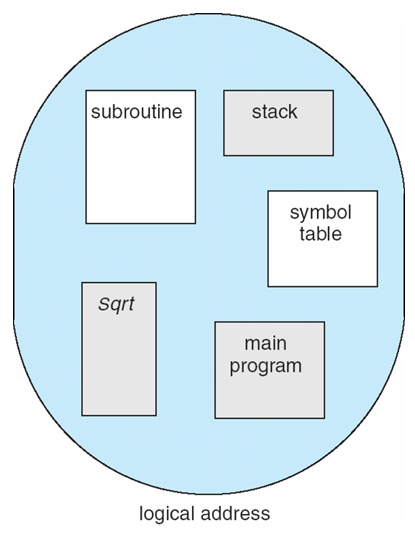
Logical View of Segmentation
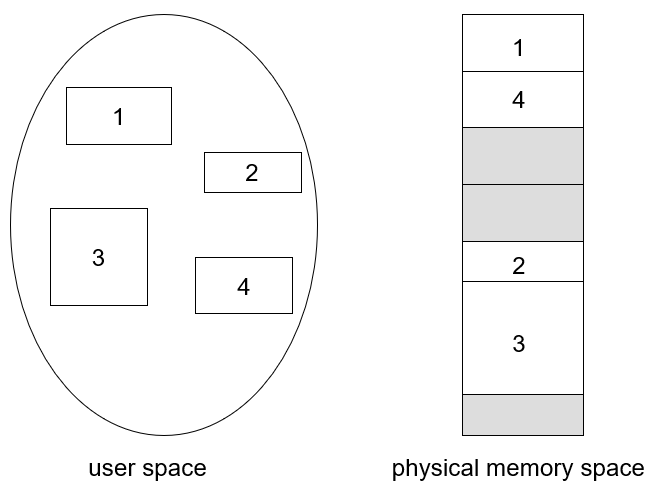
- 각각의 hole을 분리해서 프로세스의 구성요소를 넣음
- 메모리 활용도 높아짐, 연속적인 공간에 저장하는 것보다 훨씬 빨리 수행 가능
Segmentation Architecture
- 논리 주소는 두 개의 튜플로 구성: <segment-number, offset>
- Segment table – 2차원 물리적 주소를 매핑, 프로세스가 스케줄링 될 때 만들어져 메모리 안에 저장
- 각 테이블 항목에 있는 것
- base – 세그먼트가 메모리에 있는 시작 물리 주소를 포함
- limit – 세그먼트의 길이를 지정
- 각 테이블 항목에 있는 것
- offset < limit 일 때, base + offset로 physical address 결정
- Segment-table base register (STBR) - 세그먼트 테이블의 메모리 위치(address)를 가리킴
- Segment-table length register (STLR) - 프로그램에서 사용되는 세그먼트 수를 나타냄, segment table 전체 길이
- segment number s < STLR인 경우 옳음
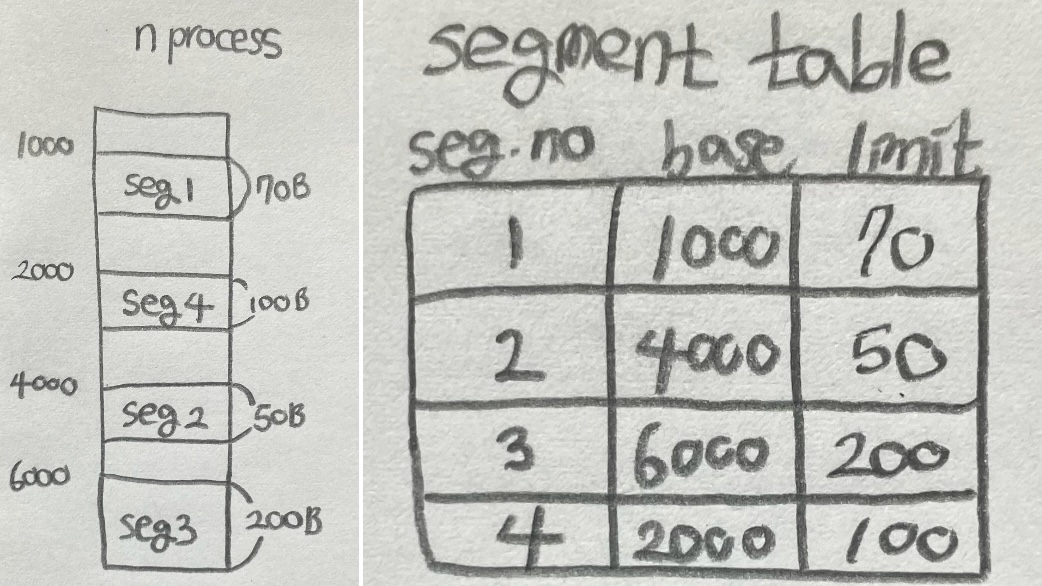
- (1, 10) logical address 발생 → physical address : 1000 + 10 = 1010 (10<70)
- (4, 110) logical address 발생 → trap 발생 (110>100)
- (4, 90) logical address 발생 → physical address : 2000 + 90 = 2090 (90<100)
Segmentation Architecture (Cont.)
- 장점
- Sharing
- 여러 프로세스에서 공유되는 코드 부분을 한 개의 segment 안에 통째로 집어 넣을 수 있음
- Protection
- segment table의 각 항목과 연결:
- validation bit = 0 → illegal segment, 프로세스가 접근 x 세그먼트, bit로 segment 보호
- 읽기/쓰기/수행 권한
- segment table의 각 항목과 연결:
- Sharing 하는 부분 혹은 Protection 하는 부분을 한 segment 안에 통째로 집어 넣을 수 있음
- Sharing
- 세그먼트와 연결된 protection bits; 세그먼트 레벨에서 코드 공유 일어남
- 세그먼트 길이가 다양하기 때문에, 메모리 할당은 동적 스토리지 할당 문제임
- 다음 다이어그램에는 segment 예제가 나와 있음
Segmentation Hardware
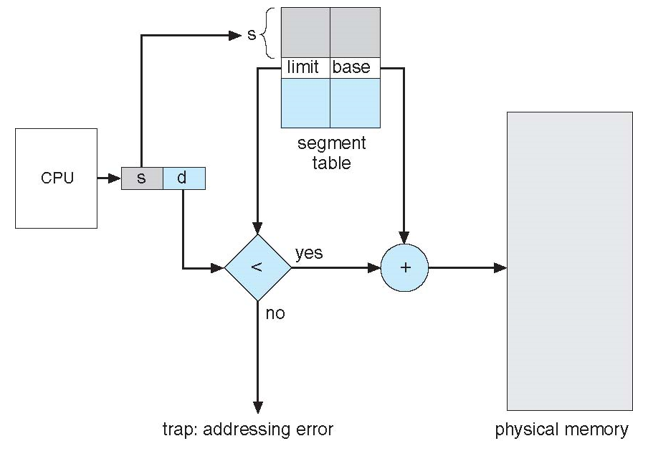
- d = displacement, offset
Paging
- 프로세스의 물리적 주소 공간은 비연속적일 수 있음, 프로세스는 프로세스가 사용 가능할 때마다 물리적 메모리가 할당됨
- 외부 단편화(external fragmentation) 방지
- 다양한 크기의 memory chunk 문제 방지
- physical memory를 frames이라고 하는 고정 크기의 블록(fixed-sized blocks)으로 분할
- 크기는 2의 거듭제곱(512바이트에서 16MB 사이)
- logical memory를 pages라는 동일한 크기의 블록으로 분할
- 모든 사용 가능한 프레임 추적
- N pages 크기의 프로그램을 실행하려면, N개의 free frames을 찾고 프로그램을 로드해야 함
- logical addresses를 physical addresses로 변환하도록 page table 설정
- 마찬가지로 여러 pages로 분할된 backing store(백업 저장소)
- 여전히 내부 단편화(Internal fragmentation) 존재
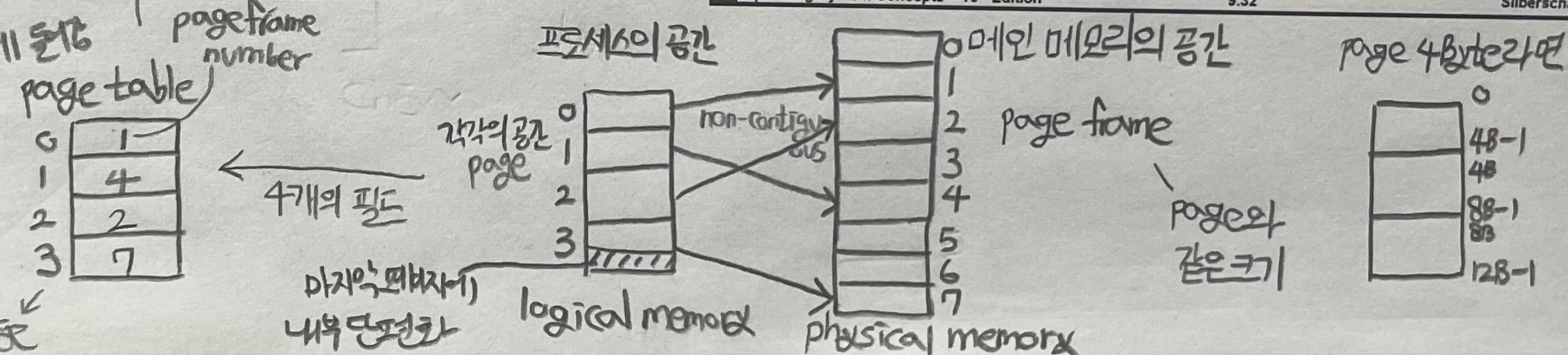
- 프로세스의 공간 = logical address space, 메인 메모리의 공간 = physical address space
- page table의 page number 각각은 page table entry
- 내부 단편화(internal fragmentation)가 프로세스가 할당된 마지막 page frame에 발생
- 각 페이지의 start address 자동으로 계산, page 크기 = page frame 크기 → base, limit 필요 x
- 프로세스가 context switch 될 때 page table이 메인 메모리 안에 저장됨
- page size = 4B → 0번째 바이트, 바이트 1, 바이트 2, 바이트3
- ex) logical address = 10, page size = 4B
- 10/4 = (2, 2) (page number, page offset)
- (2, 2) (page frame number, offset)
- 4B x 2 + 2 = 10B → page number 10에 저장
Address Translation Scheme
- CPU에서 생성된 주소는 다음과 같이 나뉨
- Page number (p) – physical memory에 있는 각 page의 base address를 포함하는 page table의 인덱스로 사용 (몇 번째 페이지인지를 나타냄, page table entry)
- Page offset (d) – base address와 합쳐져, 메모리 장치로 전송되는 physical memory address를 정의 (해당 페이지에서 몇 번째 떨어진 곳인지 displacement를 나타냄, maximum은 page size)

- n bit → 메모리 공간 2^n
- 전체 논리 주소 공간(한 프로세스가 가질 수 있는 최대 크기) m bit → logical address space 2^m
- page size 2^n
- 2^(m-n) x 2^n = 2^m → 총 논리 페이지 개수 x 페이지 사이즈 = 총 사이즈
- ex) 16 pages, 8 page frames, page size 4B
- 프로세스가 가질 수 있는 최대 공간 = 16 x 4B = 64B
- physical address space(물리 주소 공간) = 8 x 4B = 32B
- 1bit로 2^1개 표시, 2bit로 2^2개 표시 → 4개의 주소공간 offset으로 표시하기 위해 2 bit 필요
- logical address space = page number(4 bit) + offset(2 bit) = 6 bit → 2^6 = 64B
- physical address space = page frame number(3 bit) + offset(2 bit) = 5 bit → 2^5 = 32B
- page table entry 개수 = 2^4개 (page의 개수)
- page table을 메인 메모리에 저장하는 데 드는 공간 = 한 entry를 저장하는 데 드는 공간 x page table entry 개수
- if 한 entry를 저장하는 데 드는 공간 = 1B → 1B x 16 = 16B
- ex) logical address space = 4bit, page size 2 bit
- page number = 2 bit → 2^2 = 4개의 페이지
- page offset = 2 bit → 2^2 = 4B의 주소공간
- 전체 주소 공간 = 4 x 4B = 16B
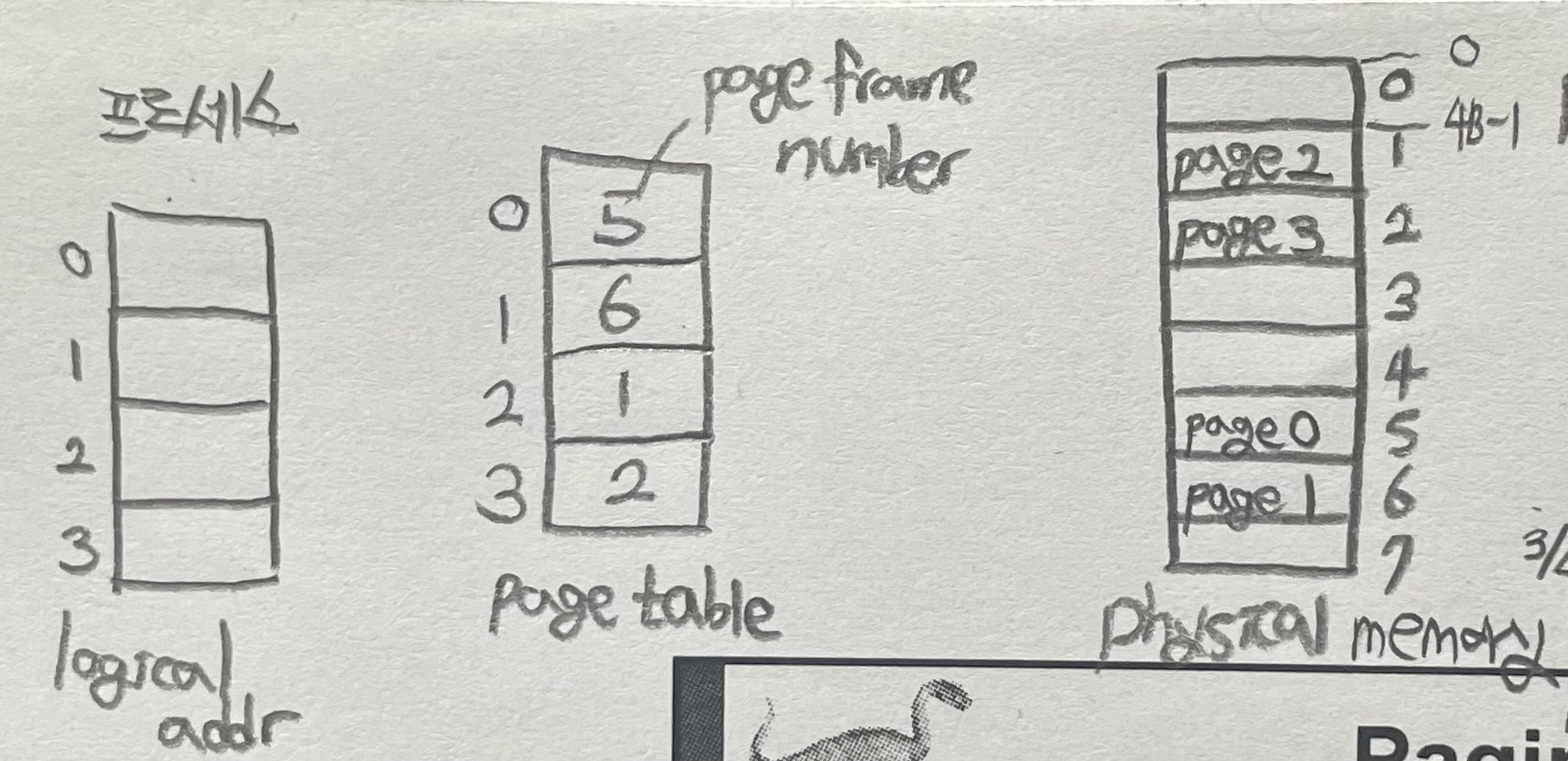
- page size = 4B
- physical address = page frame x a page frame's size + offset
- logical address = 0 → 5 x 4 + 0 = physical address 20에 저장
- logical address = 3 → 3/4 = 0 → (0, 3) → 5 x 4 + 3 = 23
- logical address = 4 → 4/4 = 1(logical page number) → (1, 0) → 6 x 4 + 0 = 24
- logical address = 13 → 13/4 = 3 → (3, 1) → 2 x 4 + 1 = 9
Paging Hardware
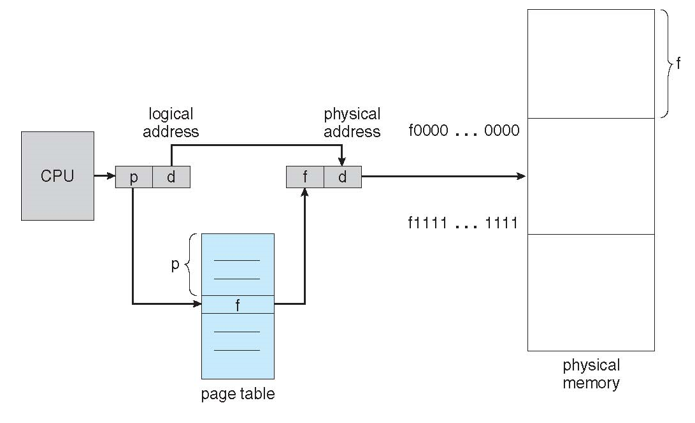
- p → logical page number
- d → displacement
- f → page frame number
- logical address / page size → page number, offset
- physical address = f x page size + d
- page table 안에서 page number을 인덱스로 page frame number 찾기
- offset을 고려해서 최종 instruction or data를 물리 주소로부터 가져옴
Paging Model of Logical and Physical Memory
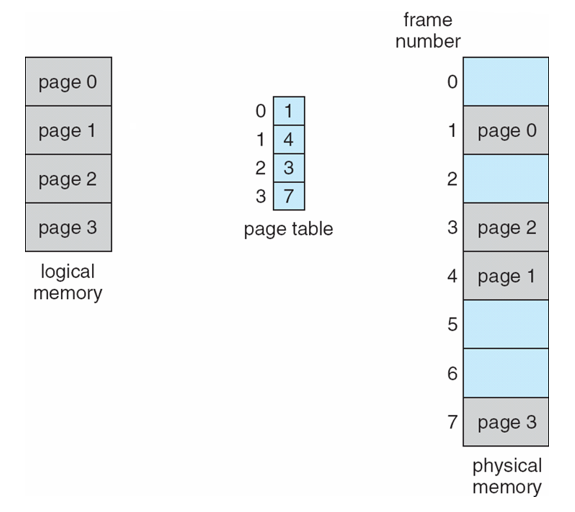
Paging Example
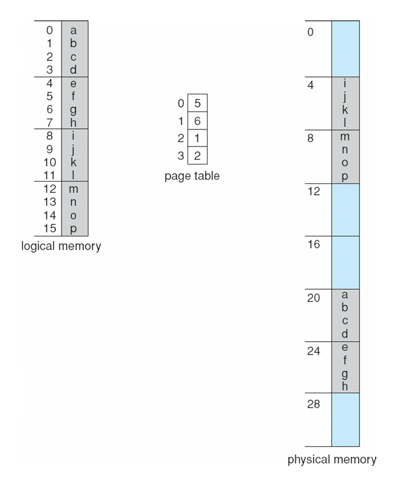
- n=2, m=4 32-byte memory and 4-byte pages
- page size = 4B
- n = 13, 13/4 → (3, 1) (logical page number, offset) → 2 x 4 + 1 = 9
- g = 6, 6/4 → (1, 2) (logical page number, offset) → 6 x 4 + 2 = 26
Ex) 연습문제 9.4
- page size = 1024 = 2^10 w, logical page = 64 = 2^6 pages, physical page frame = 32 = 2^5 page frames
- logical address space → page number = 6 bit, page offset = 10 bit → logical address space = 2^16 w
- page table entry → 64개
- physical address space → page frame number = 5 bit, page offset = 10 bit → 2^15 w로 physical page 구성(물리 메모리 총 크기)
Ex) 연습문제 9.9
- physical memory = 64 KB = 2^16 B → 16 bit로 physical address space 표시
- page size 4KB = 2^12B → 12 bit 필요
- page frame number = 4 bit → 2^4 개의 page frame 존재, page offset = 12 bit
- 256 page → logical address space = 2^8 (logical page 개수)
- 전체 논리 주소 공간 → 2^8 x 2^12 = 2^20 B (page number 8 bit, page offset 12 bit)
- 전체 물리 주소 공간 16 bit, page offset 12 bit → page frame number = 16 - 12 = 4 bit (16개의 page frames)
- page table entry 개수 = 2^8개
- if 한 entry 저장하는 데 1B 필요 → page table 저장할 때 드는 메모리 공간 2^8 x 1B = 256B
Paging
Internal fragmentation 계산
- Page size = 2,048 bytes
- Process size = 72,766 bytes
- 35 pages + 1,086 bytes
- Internal fragmentation of 2,048 - 1,086 = 962 bytes
- Worst case fragmentation = 1 frame – 1 byte (최악의 경우 2047 bytes, 최대 internal fragmentation size)
- On average fragmentation = 1 / 2 frame size
- frame size가 작으면 좋은가?
- 각각의 page table entry는 추적할 메모리가 필요
- 시간이 지남에 따라 페이지 크기가 증가함
- Solaris는 8KB 및 4MB의 두 가지 페이지 크기를 지원
- Process view와 물리적 메모리가 크게 다름
- 구현 프로세스는 자체 메모리에만 액세스할 수 있음
Page size 작을 때
장점
- Internal fragmentation size가 작음
- 낭비하는 메모리 사이즈가 작음
단점
- 페이지의 개수가 많아져 page table entry 개수가 많아짐 → page table을 메모리 공간에 저장할 때 더 큰 메모리 공간 필요
- 프로세스를 디스크로부터 읽거나 쓰기 위해 더 많은 I/O를 실행 → I/O 속도 느려짐
- 디스크로부터 메인 메모리 안에 저장할 때 큰 덩어리를 한 번에 읽고 쓰는 것이 속도가 빠름 (나눠서 읽거나 쓰면 느림)
Free Frames
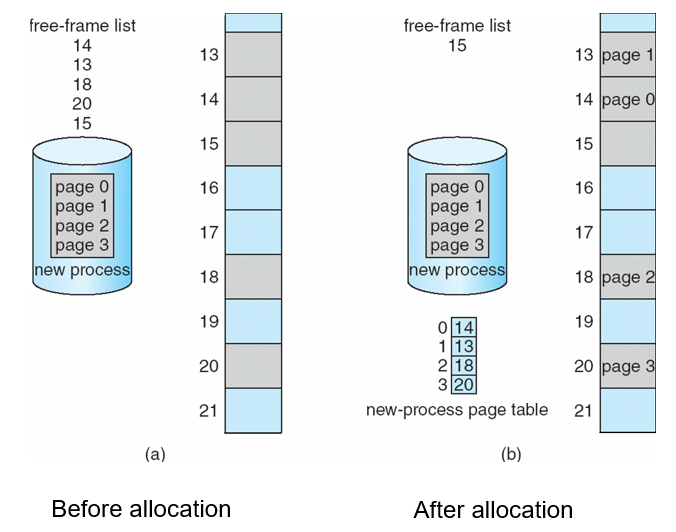
- Free Frames list 유지 → 할당 속도를 올릴 수 있음
Implementation of Page Table
- Page table이 메인 메모리에 저장
- Page-table base register (PTBR)이 page table의 시작 주소를 나타냄
- Page-table length register (PTLR)는 page table의 size(페이지 개수, page table entry 개수)를 나타냄
- 이 방식에서는 모든 data/instruction 접근에 두 번의 메모리 접근이 필요
- 메인 메모리의 page table로 가서 page frame number을 가져옴
- page frame number와 offset으로 메인 메모리의 data/instruction을 가져옴
- 두 번의 메모리 접근 문제는 associative memory 또는 TLB(Translation Look-Aside Buffers)라는 특수한 고속 검색 하드웨어 캐시를 사용하여 해결할 수 있음
- TLB = 페이지 테이블에 대한 캐시
- TLB의 각 entry는 최근에 사용된 page number, page frame number을 TLB에 저장함
Implementation of Page Table (Cont.)
- 일부 TLB는 각 TLB 항목에 주소 공간 식별자(ASID)를 저장
- ASID - 어떤 프로세스의 page number인지 알게 해주는 항목, TLB의 항목을 소유하는 프로세스에 대한 정보를 가짐
- TLB 항목 - 프로세스 넘버, page number, page frame number
- 각 프로세스를 고유하게 식별하여 해당 프로세스에 주소 공간 보호 제공
- 그렇지 않으면 모든 context switch에서 flush해야 함
- 일반적으로 작은 TLB (64~1,024개의 entries)
- TLB miss 시, 값이 TLB에 로드되어 다음 번에 더 빠르게 액세스할 수 있음
- TLB 사이즈가 작아 TLB replacement policy를 고려해야 함 (locality 고려)
- 일부 entry는 영구적인 빠른 액세스를 위해 page에 대한 page frame number가 fix
- 고정되어 있어 업데이트가 필요하지 않음 (flush x)
Associative Memory
- Associative memory – parallel search
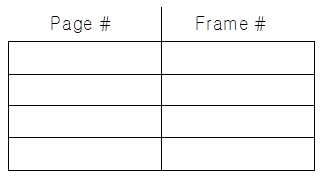
- 주소 변환 (p, d)
- p가 associative register에 있으면 Frame #을 꺼냄 (TLB에 있는 page frame number 가져옴)
- 그렇지 않으면 메인 메모리의 page table에서 page frame number 가져옴
Paging Hardware With TLB
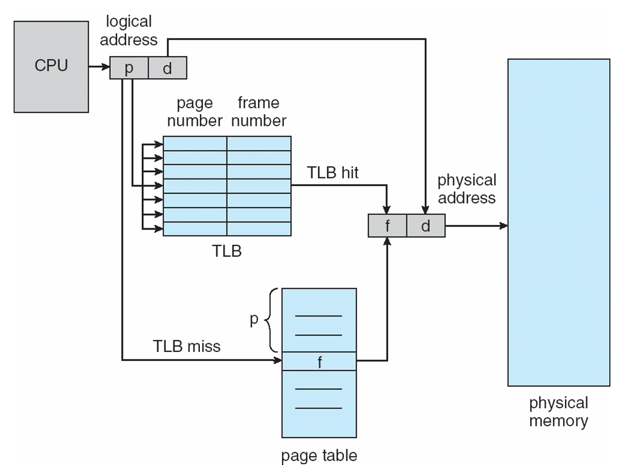
- logical address에서의 page number가 TLB에 있는지 확인
- TLB hit - TLB에서 page frame number을 찾음
- TLB miss - 메인 메모리의 page table에서 page frame number을 찾음
- offset을 고려하여 physical address로 가 instruction/data를 가져옴
Effective Access Time
- Associative 검색 = ε time unit
- memory access time의 10% 미만일 수 있음
- Hit ratio = α
- Hit ratio – associative register에서 page number가 발견된 횟수의 백분율; associative register 수와 관련된 비율
- TLB search의 경우 α = 80%, ε = 20ns, 메모리 액세스의 경우 100ns를 고려
- Effective Access Time (EAT)
- EAT = (1 + ε) α + (2 + ε) (1 – α) = 2 + ε – α
- TLB hit - (1 + ε) α
- ε: TLB에서 page frame number 찾는 시간
- 1: 메인 메모리에서 instruction/data를 가져오는 시간 (TLB에서 page frame number을 구한 다음)
- TLB miss - (2 + ε) (1 – α)
- ε: TLB에서 page frame number 찾는 시간
- 1: 메인 메모리의 page table에서 page frame number 찾는 시간
- 1: 메인 메모리에서 instruction/data를 가져오는 시간
- TLB search의 경우 α = 80%, ε = 20ns, 메모리 액세스의 경우 100ns를 고려
- EAT = 0.80 x (100+20) + 0.20 x (200+20) = 140ns
- 보다 현실적인 Hit ratio 고려 -> α = 99%, TLB 검색의 경우 ε = 20ns, 메모리 액세스의 경우 100ns
- EAT = 0.99 x (100+20) + 0.01 x (200+20) = 121ns
Memory Protection
- read-only or read-write access가 허용되는지 여부를 나타내기 위해 protection bit를 각 프레임과 연결하여 구현된 메모리 보호
- 또한 page execute-only를 나타내는 비트를 더 추가할 수 있음
- page table의 각 entry에 붙은 valid-invalid bit
- 페이지가 현재 수행되는 프로세스의 페이지인지 아닌지를 나타냄
- "valid"는 관련 페이지가 프로세스의 논리적 주소 공간에 있으므로 합법적인 페이지임을 나타냄
- "invalid"는 페이지가 프로세스의 논리 주소 공간에 없음을 나타냄, 프로세스에 속하지 않은 페이지를 나타내는 bit
- 또는 page-table length register (PTLR) 사용
- 프로세스의 page 개수가 6개일 때 page number가 7이면 이 프로세스에 속하지 않는 페이지임
- 위반 시 kernel에 대한 trap이 발생
Valid (v) or Invalid (i) Bit In A Page Table
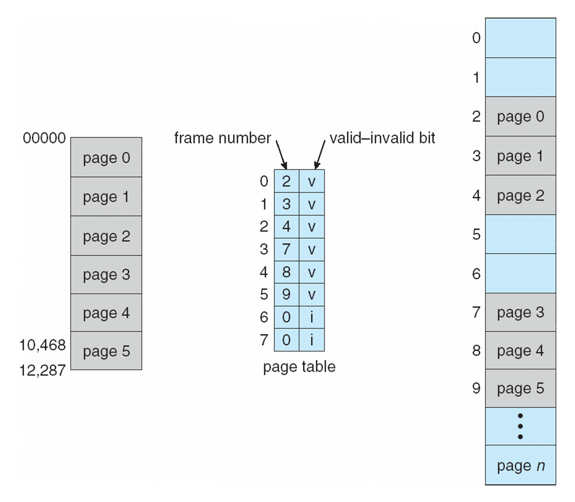
- 다른 프로세스가 침범하지 못하게 보호함
Shared Pages
- Shared Pages
- 프로세스(예: text editors, compilers, window systems) 간에 공유되는 read-only(reentrant(공유가능한)) 코드 복사본 1개
- 여러 스레드가 동일한 프로세스 공간을 공유하는 것과 유사함
- read-write pages의 공유가 허용되는 경우 프로세스 간 통신에도 유용함
- Private code and data
- 각 프로세스는 코드와 데이터의 분리된 copy를 보관
- private code and data에 대한 페이지는 논리 주소 공간의 모든 위치에 나타날 수 있음
Shared Pages Example
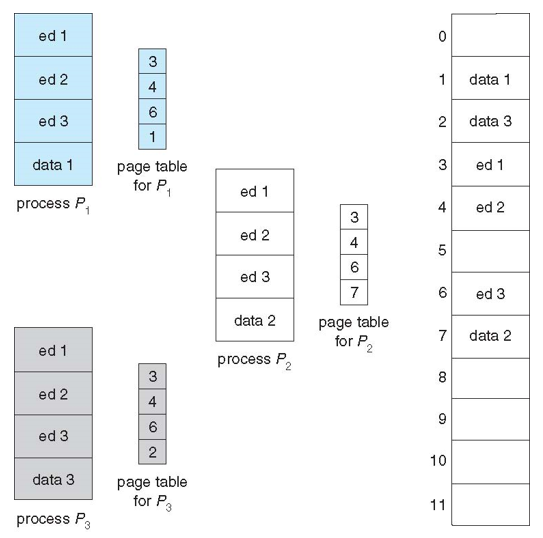
- ed 1, ed 2, ed 3 - 여러 페이지에 걸쳐 공유 가능
- data 1, data 2, data 3 - private code and data
- segmentation → 한 세그먼트 안에 code/data를 몰아줄 수 있음
- page → page size가 고정되어 공유되는 code/data가 여러 개의 페이지에 나누어 저장됨
Structure of the Page Table
- paging을 위한 메모리 구조는 straight-forward methods를 사용하여 크게 증가할 수 있음
- 32비트 논리 주소 공간을 최신 컴퓨터와 동일하게 고려
- page size 4KB (2^12B)
- page table entry의 수는 100만 개 (2^32/2^12 = 2^20)
- 각 entry가 4바이트인 경우 → page table에만 4MB (4Bx2^20)의 물리적 주소 공간/메모리
- 그 정도의 메모리는 많은 비용이 발생
- 메인 메모리에 연속적으로 할당하는 것을 원하지 않음
- Hierarchical Paging
- Hashed Page Tables
- Inverted Page Tables
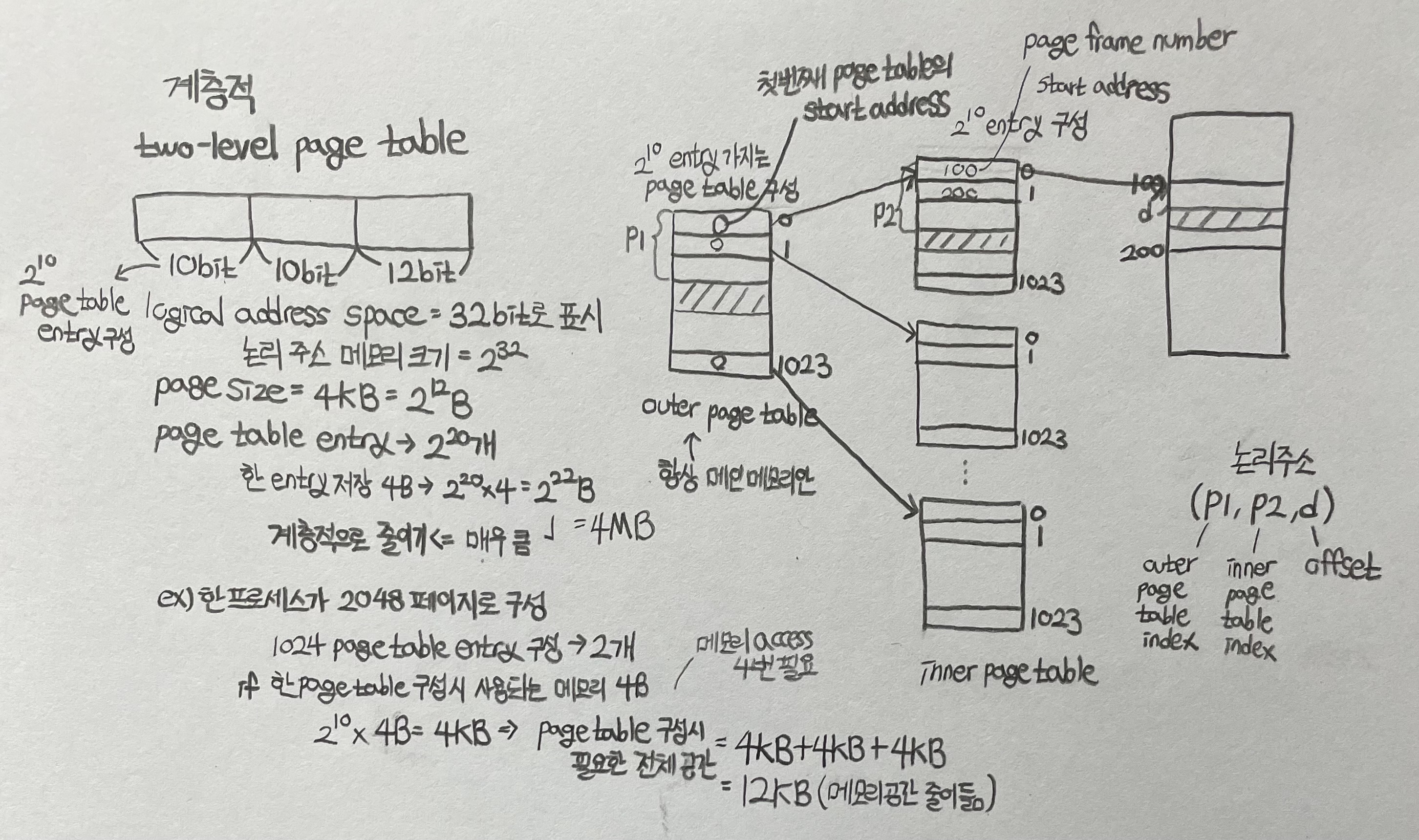
Hierarchical Page Tables
- 논리 주소 공간을 여러 page tables로 분할
- 간단한 방법은 two-level page table
- 우리는 그다음 page table을 page 함
Two-Level Page-Table Scheme
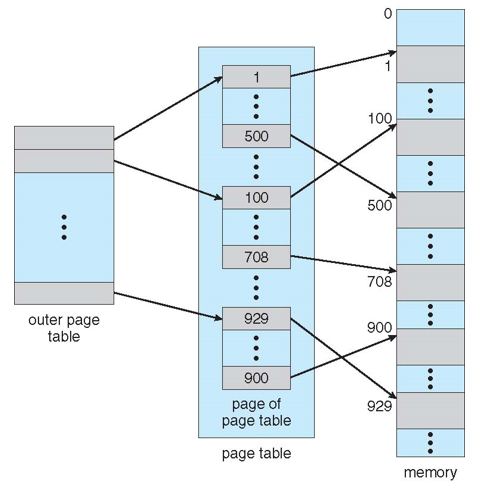
- outer page table entry에는 page table의 start address가 저장되어 있음
- 각각의 inner page table entry는 page frame의 start address를 가리킴
Two-Level Paging Example
- 1K page size, 32-bit 시스템의 논리 주소는 다음과 같이 구분됨
- 22 bits로 구성된 page number
- 10 bits로 구성된 page offset
- page table이 paged되므로 page number는 다음과 같이 추가로 구분됨
- 12-bit page
- 10-bit page offset
- 따라서 논리 주소는 다음과 같음

- p1은 outer page table의 인덱스, p2는 inner page table의 page 내 displacement (inner page table의 인덱스)
- forward-mapped page table로 알려져 있음 (outer page table로부터 안으로 들어가며 매핑이 이루어짐)
Address-Translation Scheme
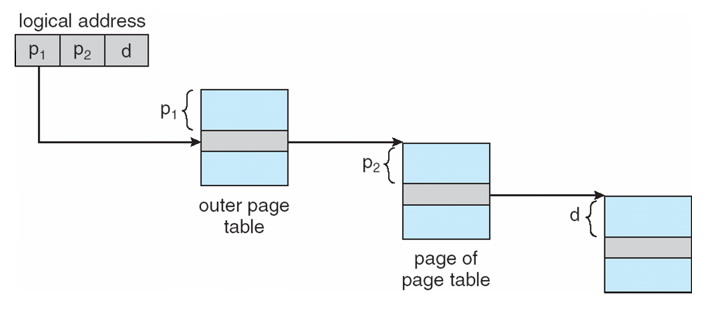
- p1 - outer page table의 인덱스
- p2 - inner page table의 인덱스
- d - 해당 page frame에서의 offset
- 마지막 색칠된 부분에 instruction/data 존재
64-bit Logical Address Space
- two-level paging 방식도 충분하지 않음
- page size가 4KB(2^12B)인 경우
- page table에는 2^52개의 entries 존재
- two-level 방식인 경우, inner page tables은 2^10 4-byte entries일 수 있음
- 주소는 다음과 같음
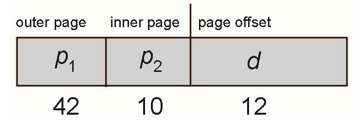
- outer page table은 2^42개의 entries or 2^44 bytes를 가짐
- 한 page table entry를 저장하는데 4B가 필요하다면 2^42 x 4B = 2^44B (16TB) 메모리 공간 필요
- 매우 큰 메모리 공간이 필요하므로 두 단계로 충분하지 않음
- 한 가지 해결책은 2nd outer page table을 추가하는 것임
- 그러나 다음 예제에서 2nd outer page table의 크기는 여전히 2^34 bytes임
- 그리고 하나의 physical memory location에 도달하기 위해 4개의 메모리 액세스가 필요함
Three-level Paging Scheme
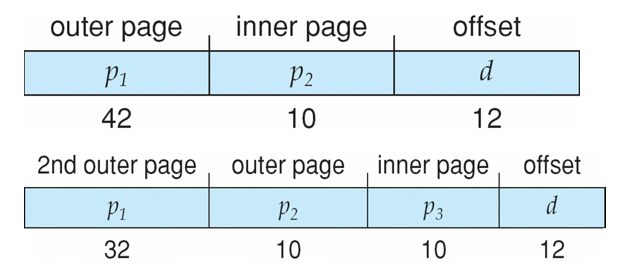
- 2nd outer page → outer page → inner page → offset
- 최소 4번의 접근이 필요
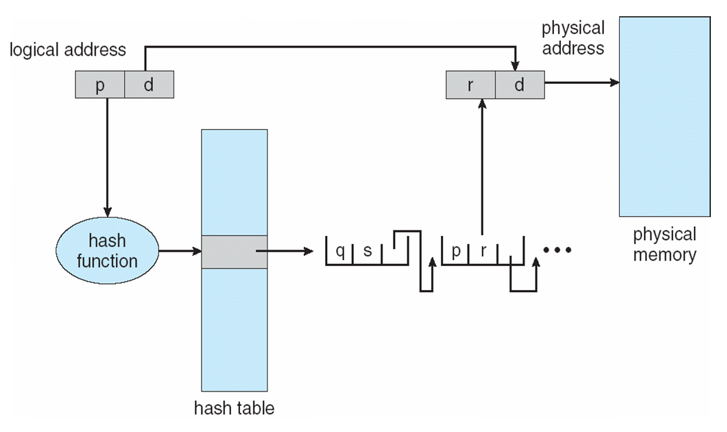
Hashed Page Tables
- 주소 공간 > 32 bits 일 때 공통적으로 사용
- virtual page number가 page table로 해시됨
- 이 page table에는 동일한 위치에 대한 요소 해싱 체인이 포함되어 있음
- 각 요소는 다음을 포함
- (1) virtual page number(page number)
- (2) 매핑된 page frame의 값
- (3) 다음 요소(entry)에 대한 포인터
- 일치 항목을 검색하는 이 체인에서 virtual page number를 비교
- 일치하는 항목이 발견되면 해당 physical frame이 추출됨
- 64-bit 주소에 대한 변형은 clustered page tables (여러 page tables로 구성)
- 해시와 비슷하지만 각 항목은 1페이지가 아닌 여러 페이지(예: 16페이지)를 참조함
- 특히 sparse address spaces(메모리 참조가 비연속적이고 흩어져 있는 경우)에 유용
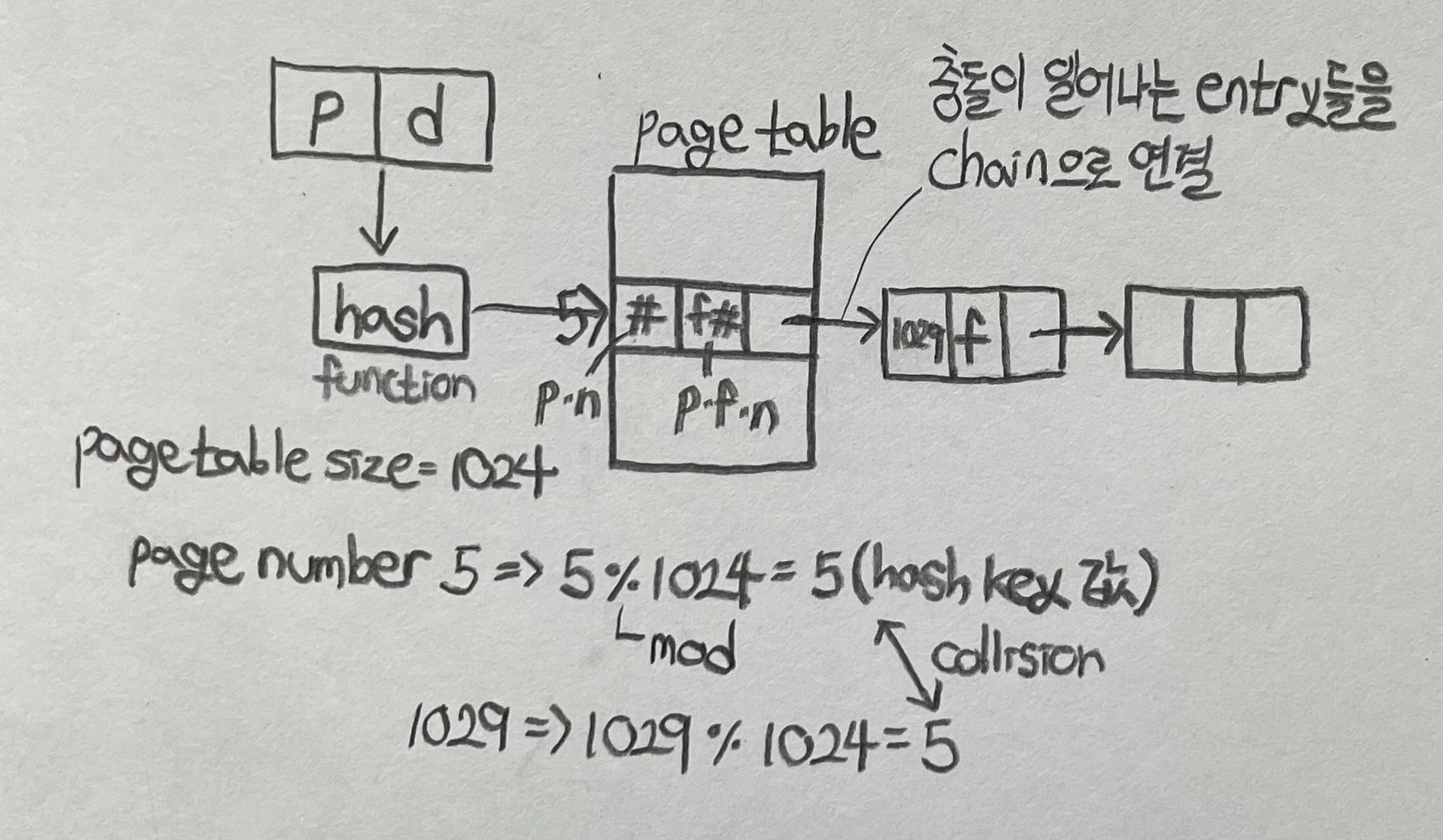
Hashed Page Table
Inverted Page Table
- 프로세스의 논리공간이 물리 공간보다 크기 때문에 page frame number로 page table을 구성하자!
- 각 프로세스에 여러 page table이 있고 가능한 모든 logical pages를 추적하는 대신, 모든 physical pages를 추적
- 메모리의 각 실제 page에 대해 하나의 entry
- entry는 해당 실제 메모리 위치에 저장된 page의 virtual address와 해당 page를 소유하는 프로세스에 대한 정보로 구성됨
- 각 page table을 저장하는 데 필요한 메모리는 줄지만, page 참조가 발생할 때 table을 검색하는 데 필요한 시간은 늚
- hash table을 사용하여 검색을 하나 또는 최대 몇 개의 page-table entries로 제한
- TLB를 통한 액세스 가속화
- 하지만 shared memory를 구현하는 방법은?
- 공유 물리적 주소에 대한 가상 주소 매핑 하나
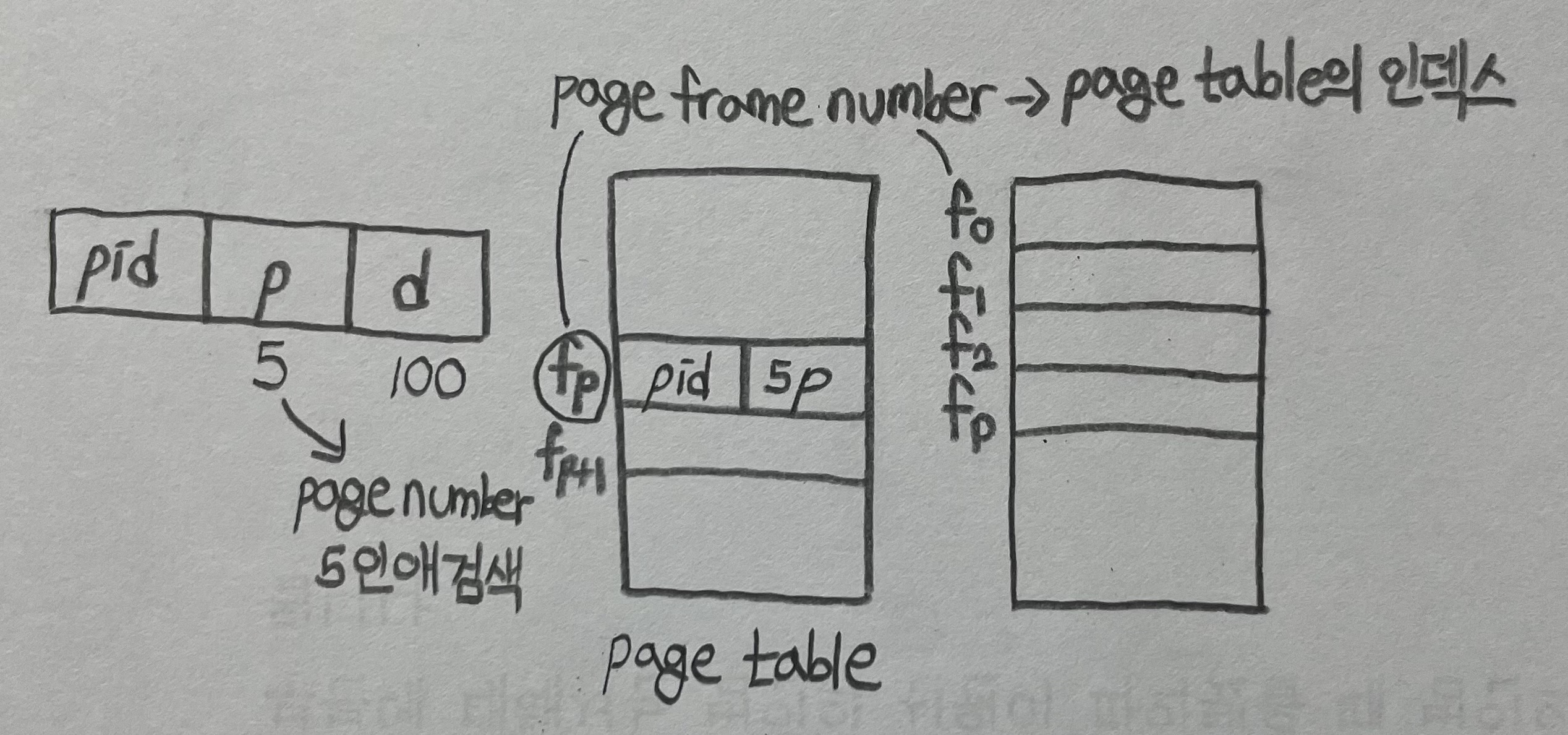
- 장점
- 메인 메모리 공간 < 프로세스 주소 공간 (메인 메모리 + disk 공간)
- page table을 저장하는 데 드는 메모리 공간이 적음
- 단점
- 한 page frame → 한 프로세스에 의해서만 사용 가능, 여러 프로세스에 의해 공유가 불가능함
- 소유하고자하는 프로세스의 pid가 존재하기 때문
- ex) 32-bit logical address, page size 4KB = 2^12B, physical memory 512MB = 2^29B, 한 page table entry 저장하는 데 1B의 메모리 공간 필요
- 1단계 page table → logical address → page number = 20 bit, page offset 12 bit
- page table entry 모두 저장하는 데 2^20 x 1B = 2^20B의 메모리 공간 필요
- inverted page table → physical address → page frame number 17 bit, page offset 12 bit
- page table entry 모두 저장하는 데 2^17 x 1B = 2^17B의 메모리 공간 필요
- 1단계 page table → logical address → page number = 20 bit, page offset 12 bit
Inverted Page Table Architecture
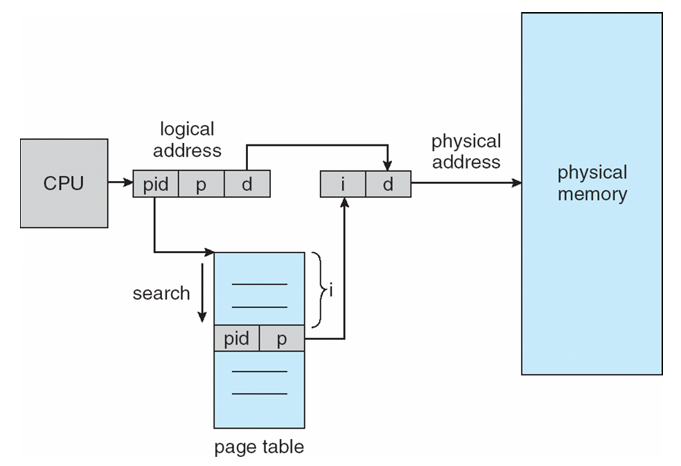
- search 되는 인덱스는 page frame number
참고 자료 : Operating System Concepts - 10th edition, Sliberscahatz, Galvin and Gagne
'CS > 운영체제' 카테고리의 다른 글
| 운영체제 ch 10. Virtual Memory (0) | 2023.06.09 |
|---|---|
| 운영체제 ch 8. Deadlocks (0) | 2023.05.03 |
| 운영체제 ch 7. Synchronization Examples (0) | 2023.05.02 |
| 운영체제 ch 6. Synchronization Tools (0) | 2023.04.18 |
| 운영체제 ch 5. CPU Scheduling (0) | 2023.04.12 |